








Author:Wall Street CN
Anthropic's AI programming tool, Claude Code, is facing a serious reputation crisis. The AI director from AMD publicly submitted a problem report to the official GitHub repository, accusing Claude Code of experiencing a systemic degradation in capabilities since February of this year, based on quantitative analysis of tens of thousands of session logs.Depth of thought plummeted by 67%The model's behavior was completely distorted. This report quickly sparked discussion in the developer community, putting Anthropic in the spotlight.
The analysis report was submitted by Stella Laurenzo, head of AMD's AI team. She opened an issue directly on the official GitHub repository, using strong language:Claude can no longer be trusted to perform complex engineering tasks.She stated that the team has switched to another service provider and warned Anthropic: "Six months ago, Claude stood out in terms of inference quality and execution capabilities. But now, other competitors need to be closely monitored and evaluated."
This issue quickly went viral on Hacker News, garnering 975 upvotes and 548 comments, becoming one of the most popular posts in recent Claude Code discussions. Netizen comments directly addressed the core of the problem—"ClaudeCode used to be a smart pair programming partner, but now it feels like an overly enthusiastic intern who keeps messing things up and then suggesting the simplest temporary solutions."Lately, they keep telling me things like, 'You should go to sleep. It's too late, let's call it a day.' At first, I thought I had accidentally let Claude know my deadline."
Anthropic responded to this. Boris, a member of the Claude Code team, clarified that the redact-thinking feature is only a change at the interface level and "will not affect the actual reasoning logic inside the model, nor will it affect the thinking budget or the underlying reasoning mechanism."
He also acknowledged that the team made two substantial adjustments in February:First, the "adaptive thinking" mechanism was introduced with the release of Opus 4.6 on February 9th; second, the default effort level was adjusted from high to medium on March 3rd.Boris recommends that users manually resume high-effort thinking mode using the /effort high command or by modifying the configuration file.
However,This explanation did not quell the community's doubts.Several developers stated that even with effort set to the highest level, the "eager to finish the task" mentality of slacking off persisted. User richardjennings commented:
"I had no idea the default effort had been changed to Medium before the output quality plummeted. I spent about a whole day fixing these issues."
Data confirms: a sharp drop in the depth of thinking and a complete deviation in behavior.
Laurenzo's analysis is based on 6,852 Claude Code session JSONL files accumulated by his team in the ~/.claude/projects/ directory, covering 17,871 thought blocks, 234,760 tool calls, and more than 18,000 user suggestions. The time span extends from the end of January to the beginning of April 2026, and the entire process uses the Anthropic official API to directly connect to the Opus model.

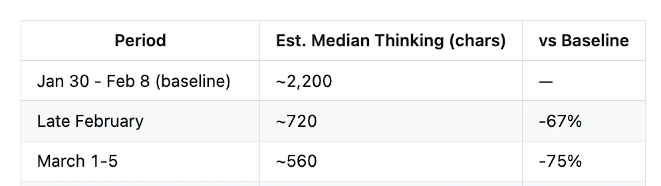
The data reveals a clear timeline of degradation.During the "prime period" from January 30 to February 8, the median depth of thought in Claude Code was about 2,200 characters; by late February, this number had plummeted to about 720 characters, a drop of 67%; and by early March it had further shrunk to about 560 characters, a drop of 75%.
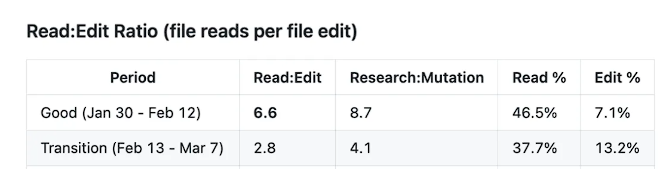
The collapse of depth of thought directly triggered a fundamental shift in the way tools are used.During its high-quality phase, Claude Code's read-to-modify ratio (the number of file reads before each edit) was as high as 6.6, adhering to a rigorous workflow of "research first, then modify." However, during the "degradation phase" after March 8th, this ratio plummeted to 2.0, with research input decreasing by approximately 70%. Even more alarmingly, during the degradation phase, one out of every three code modifications was made without reading the target file—directly leading to frequent low-level errors such as code being inserted in the wrong place and the semantic relationships of comments being broken.
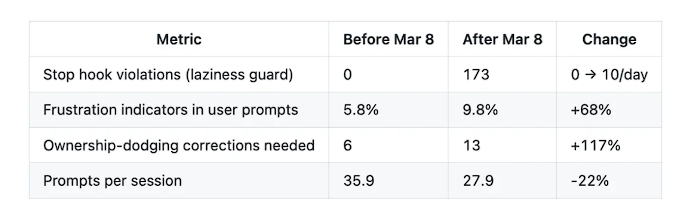
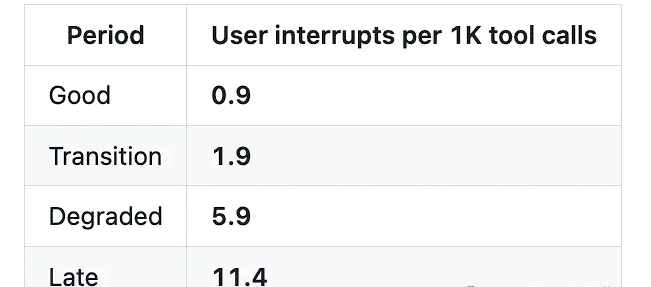
The quantitative indicators at the behavioral level are equally alarming.The termination hook script (stop-phrase-guard.sh), used to catch misbehaviors such as "shirking responsibility, premature termination, and requesting permission," was never triggered before March 8th; however, in the 17 days that followed,The number of triggers surged to 173, averaging 10 times per day.The proportion of negative emotions in user prompts rose from 5.8% to 9.8%, an increase of 68%; the user interruption rate (i.e. the frequency at which users discover that the model has made a mistake and forcibly terminate it) soared 12 times from the high-quality period to the later period.
Hidden "Thought Content Hiding" Function: Degeneration is Deliberately Concealed?
Laurenzo's analysis points out that the aforementioned degradation is related to a phenomenon called...redact-thinking-2026-02-12The deployment timeline of the feature is highly consistent. Data shows that the feature was rolled out in a phased manner (1.5%) on March 5, and by March 10-11 it had covered more than 99% of requests, and was fully effective from March 12.
This feature strips away the thought process from the API response, preventing users from externally observing the model's actual reasoning process. Laurenzo believes this design objectively makes the degradation of thought depth invisible to the user—"3The hidden feature launched at the beginning of the month simply makes this degradation invisible to users."
She further pointed out that the decline in thinking depth actually began earlier than the feature's launch, starting in mid-February. This coincides with Anthropic's release of Opus 4.6 on February 9th, introducing the "adaptive thinking" mode, and adjusting the default thinking level to "Medium effort" (effort=85) on March 3rd.
The report also found that,The depth of thought exhibits significant time-based fluctuations after the hidden feature was launched.— 5:00 PM Pacific Time (the end of the workday on the US West Coast) is the worst time of day, with a median estimated thought depth of only 423 characters; 7:00 PM is the second worst time, with only 373 characters.
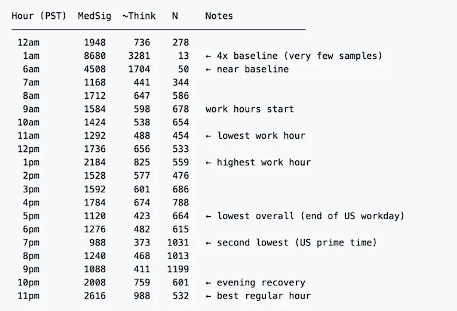
This pattern does not conform to fixed budget allocation and is closer to the characteristics of a load-sensitive dynamic allocation system, suggesting that resources may fluctuate in real time with the platform load.
Anthropic's official response: It's a settings issue, not model degradation.
In response to the rapid escalation of the issue on GitHub, Boris, a member of the Claude Code team, responded within hours on both GitHub and Hacker News, acknowledging the existence of some of the problems and providing technical explanations.
Boris's key clarifications include:
- First, the redact-thinking feature is a UI-level change and does not affect the actual reasoning process. Users can restore its display using the showThinkingSummaries: true option in settings.json.
- Secondly, the decrease in thinking depth in late February was mainly related to the introduction of adaptive thinking mechanism in Opus 4.6 on February 9 and the adjustment of the default effort level to medium on March 3. The former can be turned off by CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING=1, and the latter can be manually increased by /effort high or /effort max.

Boris also stated that the team plans to test adjusting the default effort level to high for Teams and Enterprise users, and is investigating the issue raised by some users regarding insufficient reasoning allocation in certain rounds by the adaptive thinking mechanism.
However, this explanation has sparked widespread skepticism within the community. User koverstreet responded:
"The problem goes far beyond simply changing the default thinking level to medium. Even with effort set to the highest, the model's 'eager to complete the task' behavior of slacking off has significantly increased."
Some users directly pointed out that the original report submitter had used all known public settings at the time of submission, so the problem was not due to misconfiguration. One user sarcastically asked:
"What kind of spirit is this—telling users 'you've messed up the settings'?"
Cost collapse and user exodus
The cost of degradation is not only a loss of quality, but also a catastrophic increase in costs.
Laurenzo's data shows that from February to March, the number of user suggestions for its team remained almost flat (5,608 vs 5,701), but the number of API requests surged 80 times, the total number of input tokens increased 170 times, the number of output tokens increased 64 times, and the monthly cost estimated by Bedrock Opus pricing soared from $345 to $42,121, an increase of 122 times.
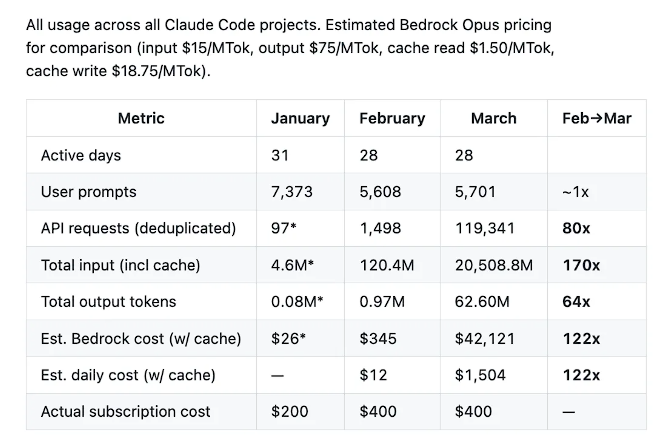
Laurenzo explained that the soaring costs stemmed partly from the team's proactive scaling up of concurrent agents, but the degradation itself caused invalid loops, frequent interruptions, and retries, amplifying the number of API requests consumed per unit of effective work by an additional 8 to 16 times. The team was ultimately forced to shut down the entire agent cluster and revert to a single-session, manually monitored mode. Laurenzo wrote:
"The amount of human effort remained almost unchanged, but the model consumed 80 times more API requests and 64 times more output tokens, yet produced significantly worse results."
In discussions on Hacker News, numerous users expressed similar experiences, with some announcing their switch to OpenAI Codex or other alternatives. "I've canceled my subscription and switched to Codex"; "Now using Qwen 3.5-27b, although not as sharp as Opus from two months ago, we can get our work moving normally again."
User Self-Help: Temporary Response Plan
Faced with degradation, some developers have explored several temporary coping strategies.
Explicit authorization in CLAUDE.md is the most common practice—by writing instructions such as "You have the right to edit any file in this project" and "Do not request confirmation during refactoring" in the configuration file in the project root directory, the frequency of security interruptions can be reduced by about 70% in practice.
Breaking down complex tasks into clearly defined subtasks has also been widely proven effective. Compared to "refactoring the entire authentication system," instructions with clear boundaries, such as "refactoring only auth.js and outputting a change summary upon completion," can significantly reduce premature termination of the model.
At the settings level, adjust effort to high or max, and then...CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING=1Disabling adaptive thinking is currently the most direct intervention method officially recognized.
Laurenzo, in its report, raised a more systematic demand: Anthropic should publicly disclose the distribution of its ThinkTokens, launch a dedicated "Full Think" subscription tier for complex engineering workflows, and expose this in its API responses.thinking_tokensThis field allows users to independently monitor whether the inference depth meets the target.




















![When copper prices rise, who is buying, who is pushing up prices, and who is buying on dips? [Peifengke Master Class 3.1]](http://img.528btc.com.cn/pro/2026-04-07/img/1775556730039cc9499b27xjjh6h6ba865524b31x86h8.jpg)
