








Author:Wall Street CN
The explosive adoption of generative AI is reshaping the competitive landscape of the entire semiconductor industry. The core battleground of the AI chip market is structurally shifting from the model training stage to the inference stage—a shift that not only concerns chip design priorities but will also profoundly impact infrastructure investment logic, business models, and the long-term trajectory of the semiconductor supply chain.
The surge in inference demand is already clearly evident. The explosive growth of viral applications such as Ghibli-style image generation has brought OpenAI's GPU resources to a near standstill. OpenAI CEO Sam Altman publicly stated that he has never seen such rapid growth in usage, forcing GPT-4.5 to be released in phases, initially only available to paying users. Leading AI companies like Meta are facing similar computing power bottlenecks. Meanwhile, OpenAI is developing its own AI chip, aiming for mass production around 2026 to reduce its reliance on Nvidia; its "Stargate" super data center project, jointly developed with Microsoft, reportedly involves an investment of up to $500 billion.
These developments indicate that AI inference is becoming a strategic pillar alongside data centers, cloud infrastructure, and semiconductors. For investors, this means…The focus of AI computing power investment is shifting: training chips represent one-time capital expenditures, while inference chips correspond to a continuous revenue consumption model—AI is evolving from a technological tool into a computing power engine that is charged on demand.
Training and Inference: Two Distinctly Different Computational Power Requirements
To understand this structural shift, we need to first clarify the fundamental differences between training and inference in terms of workload.
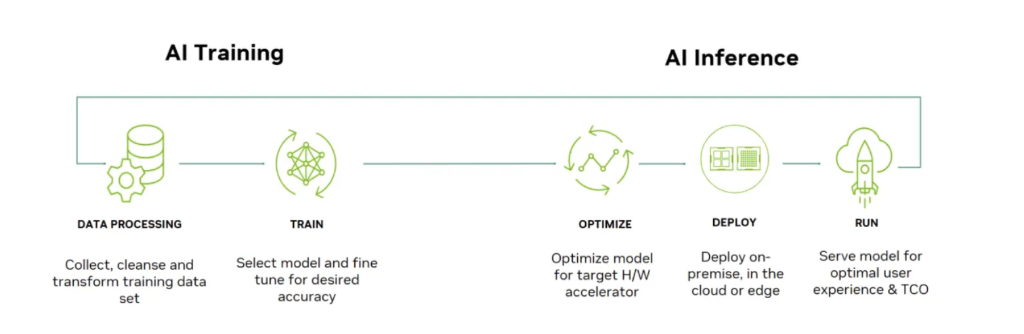
The training phase is based on Google's Transformer architecture released in 2017. It requires forward and backward propagation on massive datasets and continuous updates to model weights, involving extremely large-scale matrix operations, gradient calculations, and parameter updates. It typically requires distributed computing on multi-GPU or TPU clusters for weeks or even months. Therefore, the training chip must have high-density computing cores, large-capacity high-bandwidth memory (such as HBM), and horizontal scaling capabilities across multiple chips.
The inference phase is structurally simpler: it only requires forward propagation, without gradient updates or backpropagation, and typically requires an order of magnitude less computational power than training. However, the real challenge of inference lies in the triple constraints: low latency (users expect instant response), high throughput (service providers must handle massive concurrent queries), and low cost (the unit cost of each query directly impacts commercial viability). These requirements are diametrically opposed to the training phase's logic of "disregarding latency and pursuing ultimate performance," and dictate that inference chips must adopt a differentiated architectural design: prioritizing energy efficiency, optimizing data movement, maximizing memory and bandwidth utilization, and co-optimizing hardware and software.
Hyperscale cloud vendors and startups are accelerating their deployment of inference chips.
Based on these architectural differences, more and more companies are choosing to bypass Nvidia's direct competition in the training GPU market and instead build custom chips optimized for inference.
In the hyperscale cloud vendor sector, Google launched TPU (training) and Edge TPU (edge inference), Amazon deployed Inferentia and Trainium, and Meta developed MTIA (Meta Training and Inference Accelerator). Startups were equally active, with companies like Groq, Tensorrent, Cerebras, and SambaNova seeking differentiated breakthroughs in areas such as dataflow architecture, chip area allocation, power efficiency, memory access patterns, and computing core design, aiming to surpass general-purpose GPUs in inference efficiency and cost structure.
The formation of this competitive landscape is closely related to the evolution of AI application scenarios. As AI evolves from simple question-and-answer to agentic AI systems—capable of planning tasks, executing workflows, calling tools, and even replacing some human labor—the demand for inference will not only continue to grow but will also expand at an accelerated pace. The requirements of agentic systems for low latency, high memory bandwidth, and sustained computing power will further drive the strategic value of dedicated inference chips.
Nvidia: From Leader in the Training Era to Rule Maker in the Inference Era
Faced with this structural shift, Nvidia is not responding passively, but rather proactively expanding its presence in the inference market.
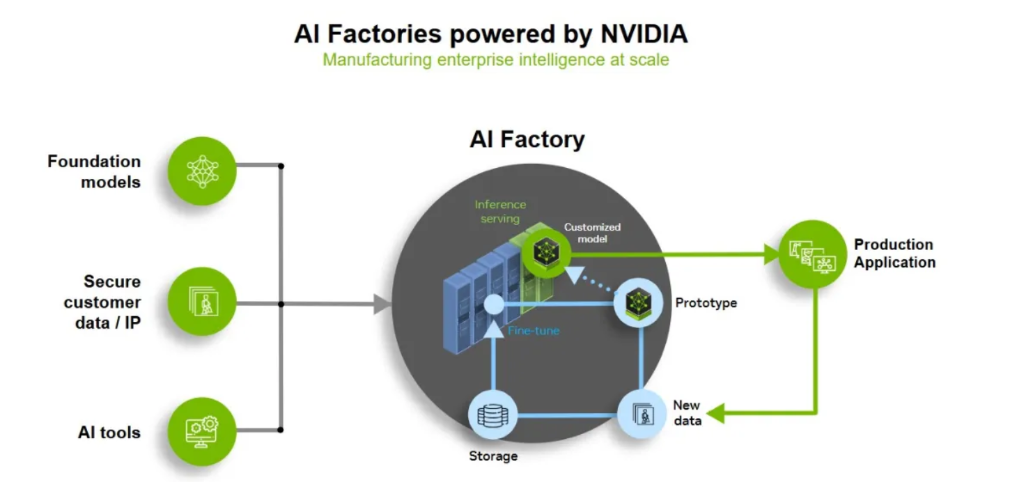
The core design goal of its latest architecture, Blackwell, is to increase throughput while reducing the cost of generating each token. This logic forms a positive flywheel: lower costs → increased usage → expanded demand → increased infrastructure scale, thereby driving the exponential growth of the AI economy. At the system level, NVIDIA, through large-scale, tightly integrated GPU clusters such as NVL72, is building an "AI factory" architecture capable of handling longer context windows, more complex inference tasks, and multi-step AI workflows, driving the evolution of AI infrastructure towards centralization, high density, and system-driven approaches.
However, Nvidia's true competitive advantage lies not only in hardware. From CUDA to TensorRT-LLM and its inference optimization software stack, Nvidia is transforming itself from a chip supplier into a full-stack AI infrastructure provider. Cloud service providers such as Microsoft, Oracle, and CoreWeave are increasingly adopting this architecture, further reinforcing the high switching costs and industry standardization effect of its ecosystem. Customers are no longer just buying GPUs, but a complete AI manufacturing platform.
Nevertheless, competition in the inference market is intensifying significantly. Inference chips are no longer a secondary option for training GPUs, but are becoming the primary computing power engine for AI cloud services, edge devices, embedded systems, and real-time applications. Driven by both hardware evolution and application expansion, the core issue of AI chip competition is undergoing a fundamental shift: from "who can train the largest model" to "who can run models with the highest efficiency in large-scale scenarios."
Structural transformation reshapes the competitive landscape of the semiconductor industry
This shift from training to inference has an impact that extends beyond chip design itself, and is deeply penetrating three dimensions: AI system architecture, business deployment strategies, and supply chain structure.
At the business model level, the economic logic of AI is undergoing a fundamental restructuring. Training corresponds to capital expenditure, while inference corresponds to recurring revenue—computing power is now directly linked to revenue as a technical metric, and GPUs are evolving from hardware devices into token generation machines. This paradigm shift means that the scale and efficiency of inference infrastructure will directly determine the profitability and competitive barriers of AI companies.
At the supply chain level, the rise of the post-training era—including the widespread application of technologies such as fine-tuning, LoRA, and adapters, as well as inference enhancement methods such as dynamic prompting structure adjustment and multi-model collaboration—is significantly increasing the reliance on inference computing power and driving the rapid expansion of demand for diversified inference hardware such as NPUs, ASICs, and FPGAs.
For investors, this structural shift signals a clear market trend: the focus of AI infrastructure investment is shifting from training to inference. Companies that can simultaneously achieve advantages in inference efficiency, cost control, and scalable deployment will take the initiative in the next phase of AI computing power competition.





















